ALLEGIANCE DATABASE
A DETAILED STUDY OF
DESIGN AND PERFORMANCE
Datawarehouse Database
Database Consulting Services
Saroj Das
Objective
The paramount objective of this document is to highlight the existing database design, implementation, performance advantages, disadvantages and throughput. The analytical projection of various database parameters and configurations will facilitate and gauge the database capability with respect to the applications need.
The database of Allegiance adheres to its missions critical application of manifold dimensions. This has been a prudent attempt to distribute the application onto the corresponding server and database. The focal point is to evaluate the database design and configuration so that it can accommodate the increasing need of the business process.
DATABASE - The Datawarehouse Database. The database is of 200 Gigabyte size and facilitate datawarehousing for the Organization.
Note: A distributed parity-based system (RAID-5) facilitates to striping the entire disk at specific block size intervals. The block size can vary from 8KB to 128KB depending upon the database and the application requirement. If the application is read intensive, a large stripe size of 128KB is more conducive. If the application is transaction intensive, a moderate size between 16KB to 64KB (i.e. depending upon the amount of physical write, in case of large batch write, large stripe size is helpful) provides an adequate I/O balance. A valuable rule of thumb to follow is to ensure that the stripe size is substantially greater than the I/O block size. This will minimize the impact of the read overhead. Stripe sizes of 64KB to 128KB are commonly used in database configurations. Existing configurations with respect to the business process needs is discussed later in this document.SERVER - Digital 8400Processor: 6 x DEC-ALPHA (64 Bit) 625 MHz
Memory: 4 Gig
Controller: 7 x Disk Array
RAID: 5+1 (Mirroring and Distributed Parity - based system)
Write Cache: Enabled
Stripe Size: 128KB block size
Disk Space: There are 7 dual controllers on the server. Each controller is comprised of 5 RAID-5 sets and each RAID set is comprised of six 2Gig disks (i.e. 6 x 2Gig = 12Gig). The disk distributions are as follows:
The total usable disk size (i.e. available for user) is 350 Gig.3 x 2 Gig On RAID Level - 17x(5x(6x2)) On RAID Level - 5
------------
Total 420 Gig
RAID IMPLEMENTATION
RAID Level-5 (i.e. block striping with distributed parity) and RAID Level-1 are implemented on the Server. In RAID-5, the data is stored, as are check sums and other information about the contents of each disk array. If one disk is lost, the others can use this stored information to recreate the lost data. The advantages, disadvantages and cost on performance of implementing RAID Level-5 is discussed later in this document. RAID Level -1 performs disk to disk mirroring. Therefore, the RAID configuration is a combination of RAID 1+5. The design considerations of having RAID 5+1 are discussed later.Database Snapshot (Tab - 1)
| Instance Name | SGA Size | Archive Mode | Rollback Segments Name Ini Size In MB | Total Number of Tablespaces | Total number of Datafiles & Total Size | Total Number of Tables | Total Number of Indexes | Total Number of Users |
| 1.B001
[Data Warehoue]
|
2 Gig
|
Enabled
|
SYSTEM
ROLLBACKM01 ROLLBACKM02
|
0.23
200 200 |
|
|
241
|
337
|
1516
|
| P.S. : All the rollback segments initial size is 200 MB and expandable up to 2 Gig. | |||||||||
Designing Consideration
All the above datafiles have been created on the DISK having RAID Level - 5. The design is a combination of a number of small and large tablespaces. It is imperative to consider creating large tablespace sized by a single large datafile in case of RAID based DISK configuration, since the disk partition is carried out by the RAID mechanism. Creating multiple tablespace / datafile of a small size will not benefit much from the RAID system. In addition, the data warehouse application, which features large batch writes and many small or large queries obtain a maximum benefit by assigning large datafiles. By assigning large datafiles, a larger number of contiguous blocks can be acquired for both large physical reads and large writes. This makes the access faster. It has been noticed that there are many small tablesapces sized by small datafiles implemented on the database. It is suggested that if such tablespaces can be re-organized to large datafiles, a substantial performance gain can be achieved. The RAID configuration with respect to distribution and its ramification is discussed later.
Note: The tablespace design and datafile allocation has been carried out according to random requirement (i.e. transactional database) rather than data warehouse database. For example, to constitute a tablespace of 2Gig size, four datafiles of 500MB each have been created and allocated on mountpoints of either different RAID sets or different controllers ( tablespaces DATA14, DATA80, DATA81).
Lets illustrate the tablespace design. ( tablespace DATA80 or DATA81):
The datafile allocation for the tablespace is considerably geometrical. Many datafiles of different sizes (there is no uniformity of the size) have been created on different mountpoints. If you notice in Tab-2, the scenario is the same with many other tablespaces.Tablespace Data Files Size In MB Free In MB-------------------- -------------------------------- --------- ----------
DATA81 db09/oradata/B001/data81_02.dbf 401 1
db13/oradata/B001/data81_01.dbf 301 1
db15/oradata/B001/data81_02.dbf 101 1
db28/oradata/B001/data81_04.dbf 1001 501
------- --------------
sum 1804 504
Lets illustrate the filesystems (i.e. mountpoints) design and distribution at OS level. As discussed earlier, all the disks are configured using 7 - dual controllers and RAID-5. Each RAID set is comprised of 6x2gig disks i.e. total of 12Gig. Each RAID has been mapped as a single OS-domain and each domain has been split into two filesystems (i.e. mountpoints). This is an indication that each filesystem is potentially large enough to provide a single large space for ORACLE tablespaces in order to size it by large datafiles.
Lets illustrate the need of data warehouse database. The data warehouse database posses mainly two events at two different phases.
I Batch Read - Daily Phase
Ideal Approach: At this stage, it is clearly evident that the tablespaces are not efficiently organized. All the randomly distributed tablespaces can be re-organized to a minimum number of large datafiles. The datafiles can be limited to single or to multiple mountpoints of the same logical volume. The re-organization will accentuate the performance substantially.
The disk striping is carried out by RAID-5 by means of a designated stripe size in terms of a block. In the existing configuration, the stripe size is 128KB block. Therefore, the large datafiles are evenly striped across many disks. The technology augments the I/O distribution to great extent and reduces the contention. The database block size and single multi-block read scan with respect to RAID - 5 configuration is discussed later.
RAID Configuration
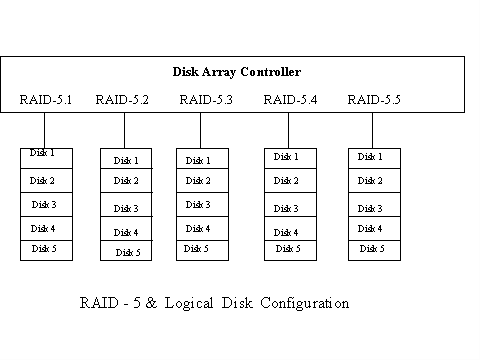
There are seven full duplex controllers on the server. On each controller, five sets of RAID-5 (i.e. logical disk array using RAID Level 5) have been configured. Each RAID-5 set is comprised of 6 x 2gigabite disks. The configuration is done in series manner and OS filesystems are independently created on each of these logical RAID sets. The configuration is illustrated on the following page.
Figure 1
Data warehouse applications, which feature large batch writes and many small or large queries, are well-suited for parity-based system like RAID-5. Small writes perform poorly in RAID-5 configurations, since the entire block and its associated parity block have to be read and written for even a small write. For example, you would have to read and write an entire 512-byte block and its parity block for a small 8-byte write operation. Read operations perform well in RAID-5 configurations because the entire block is read into the disks cache each time data from the block is requested, minimizing the time required for subsequent data requests from the same block. Reads perform twice as fast as writes in RAID-5 environments. If there are not enough read request from the application to keep all the disks in RAID set busy, full performance potential from your RAID-5 implementation will not be achieved.
1. Tablespace Allocation & Physical Object Distribution:
In most cases the tables and their corresponding indexes have been categorically
spread over different tablespaces i.e. in different set of tablespaces.
In some cases, due to the space scarcity, the distribution is carried out
between two logical RAID-5 sets (i.e. different mount points of different
logical RAID sets). For a read intensive database, a distribution across
the logical controllers is more efficient than the logical RAID sets.
Tables (Controller -1) Indexes
(Controller -2)
|
Tables
(RAID -1)
Indexes (RAID -2)
|
Rules of Distribution: When configuring striped disks, a RAID set should be counted as a logical spindle and spread tables and indexes across different logical spindles. If tables and indexes are on the logical spindles, a significant improvement will be seen for many small, random I/Os. But large I/Os going across multiple disks will result in the same spindle conflict for table and index I/Os. Therefore, to separate tables and indexes in a RAID environment, they must be stored on separate sets of RAID disks.
Existing Configuration: The tablespaces and their corresponding datafiles containing tables and indexes are spread over two different disk controllers respectively, or two different RAID sets. The design has been carried out according to the distribution rule. Therefore, in case of read and write requests, the index and table I/Os do not create any contention, rather they are equally distributed.
2. Rollback Allocation: The Rollback segments are defined in their own tablespaces and the datafiles are distributed to different disks. There are two tablespaces of 2Gig size have been created for each rollback segment. ROLLBACKM01 (segment name) with an initial size of 200MB and expandable up to 2Gig is defined in tablespace ROLLBACKM01. The ROLLBACKM02 (segment name) with initial size 200MB and expandable upto 2Gig is defined in tablespace ROLLBACKM02. The requirement of rollback segments in a data warehouse database is geometrical (i.e. the usage of rollback segment is moderate to heavy). The operation in a data warehouse database is completed in two phases; the data loading phase and the daily phase. During the data loading phase (i.e. the data-creation or conversion), rollback segment activity is significant. The daily phase (i.e. the decision support queries) indicates that the rollback segment is not used heavily. Therefore, it is imperative to create two or more large rollback segments and assign them for both of the phases. The design is executed in this manner so that in case of heavy transactional loads (i.e. heavy batch writes at loading phase), the rollback segments can expand comfortably in their own tablespace. See the table below for design details.
Rollback Segment Definition: (Tab - 3)
Note: All the rollback segments are on-line.Name Ini Size Ini Ext Next Ext Min Ext Max Ext Max Size Tablespace------------ ---------- ---------- ---------- ---------- ---------- -----------
ROLLBACKM01 200MB 100MB 100MB 2 20 2Gig ROLLBACKM01
ROLLBACKM02 200MB 100MB 100MB 2 20 2Gig ROLLBACKM02
Note: The design has been carried out by keeping both the phases ( i.e. daily and batch) in mind. The batch loading has a tendency to grow abnormally in the rollback segment. On the other hand, the small random writes (the writes due to large sorts i.e. generated by adhoc queries or temporary data-creation by adhoc queries) grow with minimum usage of rollback. Therefore, by assigning above large rollback segments, adequate room has been provided for both the phases. The configuration has been completed adequately and beneficially.
3. Redo Logs allocation: There are nine redo log groups and each group has two log members of 200MB size. In order to prevent frequent log switch and database checkpoints, the log - files have been idealistically created larger to sufficiently fit large transactions into one single log file. Since more frequent check points will degrade performance and check point occurs at every log switch, it is apparent to create comparatively large log file in order to minimize log switch and check point overhead.
Redo Log Definition (Tab - 4)
Group # Members Size
---------- -----------------------------------------
3 /oracle/redo01/oradata/B001/log3aB001.dbf 200MB
/oracle/redo03/oradata/B001/log3bB001.dbf 200MB
4 /oracle/redo02/oradata/B001/log4aB001.dbf 200MB
/oracle/redo01/oradata/B001/log4bB001.dbf 200MB
5 /oracle/redo03/oradata/B001/log5aB001.dbf 200MB
/oracle/redo01/oradata/B001/log5bB001.dbf 200MB
6 /oracle/redo01/oradata/B001/log6aB001.dbf 200MB
/oracle/redo03/oradata/B001/log6bB001.dbf 200MB
7 /oracle/redo02/oradata/B001/log7aB001.dbf 200MB
/oracle/redo01/oradata/B001/log7bB001.dbf 200MB
8 /oracle/redo03/oradata/B001/log8aB001.dbf 200MB
/oracle/redo02/oradata/B001/log8bB001.dbf 200MB
9 /oracle/redo01/oradata/B001/log9aB001.dbf 200MB
/oracle/redo03/oradata/B001/log9bB001.dbf 200MB
10 /oracle/redo02/oradata/B001/log10aB001.dbf 200MB
/oracle/redo03/oradata/B001/log10bB001.dbf 200MB
11 /oracle/redo01/oradata/B001/log11aB001.dbf 200MB
/oracle/redo02/oradata/B001/log11bB001.dbf 200MB
Note: As the database is running on ARCHIVE LOG mode, the log files are automatically backed up once they fill up. So by creating more log groups and their corresponding members, the file busy archived scenario is illuminated (i.e. if one log file is being archived, the other file is available for transaction recording). In the existing configuration, by creating nine groups and two members for each group, adequate leniency has been given for moderate transaction log recording, log switching, and database check points. In addition, 90% of the total data warehouse Schema objects are created and maintained in unrecoverable mode. By doing so, the redo log usage is kept low and the speed of data load is geared to highest extent. The objects that are created in unrecoverable mode do not generate redo log information. Therefore, by performing the above redo log design, adequate room has been provided for the remaining 10% of schema objects.
The redo log files have been allocated on RAID - 1 disk sets. A significant designing step has been taken by spreading redo log files, archive log files and data files over the two different RAID sets of disks (i.e. Redo logs and Archive logs are on RAID - 1 and Data files are on RAID - 5). The philosophy of doing so is illustrated on the following page.
The major I/O bottleneck comes from disk contention problems. Disk contention problems occur due to I/O profiles that are carried out by the disk. It is sufficient to split this into two major categories: Sequential and Random I/O
Sequential I/O: In sequential I/O, data is read from the disk in order, so that very little head movement occurs. Access to the redo log files is always sequential.
Random I/O: Random I/O occurs when data is accessed in different places on the disk, causing head movement. Access to data files is almost always random.
With sequential I/O, the disk can operate at much higher rate than it can with random I/O. If any random I/O is being performed on a disk, the disk is considered to be accessed in a random fashion. Therefore, it is important to allocate redo log files and data files on two different disk sets from a performance stand point.
4. Logical Object Allocation & Distribution: The B001 database primarily deals with the data warehouse applications. The database covers three major areas of decision support:
I Common Sales Data (Schema CSD)
II Material Management & Sales (Schema DW)
III Financial Management (Schema FI)
All schemas and their mapping to corresponding tablespaces have been illustrated below.
Schema and Tablespace Allocation (Tab - 5)
|
|
|
|
|
|
DATA09
DATA10 DATA16 DATA17 DATA18 DATA19 DATA20 DATA21 *** DATA22 DATA38 DATA92 DATA93 DATA94 DATA95 DATA96 DATA97 DATA99 |
INDEX09
INDEX10 *** INDEX16 INDEX17 INDEX18 INDEX19 INDEX20 INDEX21 INDEX22 INDEX38 INDEX92 INDEX93 INDEX94 INDEX95 INDEX96 INDEX97 |
|
|
DATA07
DATA08 DATA12 DATA15 DATA21 *** DATA24 DATA25 DATA26 DATA27 DATA28 DATA29 DATA30 DATA31 DATA33 DATA34 DATA35 DATA36 DATA76 DATA77 DATA81 DATA82 DATA83 DATA84 DATA85 DATA86 DATA87 DATA88 DATA89 DATA90 DATA91 |
NDEX08
INDEX10 *** INDEX12 INDEX15 INDEX24 INDEX25 INDEX26 INDEX27 INDEX28 INDEX29 INDEX30 INDEX31 INDEX33 INDEX34 INDEX36 INDEX76 INDEX77 INDEX81 INDEX82 INDEX83 INDEX84 INDEX85 INDEX86 INDEX87 INDEX88 INDEX89 INDEX90 INDEX91 |
|
|
DATA14
DATA23 |
INDEX14
INDEX23 |
In regards to the above illustration, it is evident that all schemas have been allocated to their own tablespaces except a few (i.e. DATA21 and INDEX10) which is common between CSD and DW. The fact is known to DBAs and will be rectified soon. It is always a common and beficial practice to keep the individual schema in its own tablespace rather than share it with any other schema. By doing so, the resource contention is avoided because the queries or transactions running on one schema do not collide with the other. Particularly with the data warehouse database, where large queries against large schemas are a predominant factor, the sharing of resources can cause substantial performance problems. In the existing configuration, the approach of individual schema allocating to its own tablespace has been adopted. The strategy should be consistent and a common practice throughout the operation.
Below is the illustration of objects of the entire schema, their logical space allocation, and growth trend.
As Of Fri Jan 23 (Tab - 6)
Note: The hi-lighted objects with an asterisk have projected a high growth trend.OWN TABLE_NAME TYPE MIN EXTENTS MAX EXTENTS BYTESOBJECT STORAGE GROWTH REPORT--------------------------------------------------------------
CSD CSD_AUTO_PRC_TAB T 4 505 2550M
CSD CSD_ADEPT_IDB_LN_TAB T 9 121 9000M
CSD CSD_ADEPT_IDB_LN_WKLY T 2 121 1400M
CSD CSD_ADEPT_CONTR_TAB T 6 505 3500M
CSD CSD_DIV_CUST_PRDT_MTH T 6 505 3500M
CSD CSD_ADEPT_IDB_HDR_TAB T 4 121 3000M
CSD CSD_CMS_PRDT_TAB T 8 505 4500M
CSD CSD_CUST_VNDR_SUM T 3 121 699M
CSD CSD_KIT_TAB T 3 121 699M
CSD CSD_DEALER_TAB T 11 121 950M ***(actual 486 MB)
CSD CSD_FRT_HIST_TAB T 6 121 999M
CSD CSD_DIV_CUST_PRDT_SUM T 3 121 3000M
DW SALES_HIST_DLY T 27 505 1798M *** (actual 1024 MB)
DW PK_SALES_HIST_DLY I 22 505 1350M ***
DW PK_SALES_SMRY_RLLNG I 1 21 500M
DW PK_SKU_DTL_HIST I 12 505 670M
DW PK_SKU_DTL_DLY I 11 505 700M
DW PK_HLTH_SYS_CONTR_PRDT I 4 505 2500M
FI FI_TRANS T 50 121 750M *** (actual 407 MB)
Growth Trend of Large Objects:
Note: The above objects have projected high extent (i.e. the space allocated for tables and indexes by ORACLE in order to store the rows) growth. The allocation is more than 30%. It suggested to compress the objects to a single large extent or to minimum number of large extents (i.e. within 5 extents). The rule says, any extent allocation of an object that exceeds 25% of its maximum extent should be compressed. The high extent growth will cause ORACLE to perform a dynamic space allocation and slow down the performance. Therefore, it is imperative to maintain the objects periodically, especially those susceptible to a high extent growth.Objects Allocated Size Actual Size Pct Used Extents------------------------------------------------------------------
SALES_HIST_DLY 1798 MB 1024 MB 57% 27
PK_SALES_HIST_DLY 1350 MB 22
FI_TRANS 750 MB 407 MB 54% 50
CSD_DEALER_TAB 950 MB 486 MB 51% 11
Following are the design considerations that has been executed to accommodate a high degree of data growth for large objects:
1. System Global Area Components: This section explains the memory structure and its implications with respect to database performance. The SGA size (i.e. the real memory allocated for ORACLE) is 2 Gig. The various components that constitute SGA (in B001 database) are:
It is imperative to set high value for the above parameters for the type application that is being used on the server. The application exhibits high user calls and large database reads and writes. Therefore, by assigning a high cache value, better throughput is achieved since the majority of data access takes place in memory. The load analysis with respect to the configuration is stated below.Name Value RemarksDB_BLOCK_BUFFERS 260000 Adequate for the Application requirement
DB_BLOCK_SIZE 8192 (8 K) According to OS and adequate for the application
SHARED_POOL_SIZE 150 MB Value is more than adequate for number of SQL operations.
PS: The statistics are taken for two weeks at every one-hour interval, starting at 9AM and ending at 5PM.DB Buffer Cache Hit Ratio Report: (Tab - 7)Check Check DB Block Consistent Physical Physical Hit
Date Hour Gets Gets Reads Writes Ratios USERS
---------------------------------------------------------------
06-JAN-98 16 35533539 2061876401 155160559 1318977 92.60 49
08-JAN-98 10 71637821 4397577468 324732149 2862326 92.73 106
08-JAN-98 12 73893210 4652794109 338614842 2899491 92.84 123
08-JAN-98 13 74458632 4787559674 348077384 2907306 92.84 101
08-JAN-98 14 74794632 5022811806 357652532 2910598 92.98 103
08-JAN-98 15 75583135 5329511558 367929740 2911669 93.19 135
08-JAN-98 16 76343784 5481165612 378292806 2976296 93.19 104
08-JAN-98 17 78148161 5655507649 389381886 3101711 93.21 99
09-JAN-98 9 94732913 6360790457 416630979 3808455 93.55 100
09-JAN-98 10 96675361 6613669773 425484956 3906511 93.66 111
09-JAN-98 11 98872091 6754521008 435069469 3994490 93.65 119
09-JAN-98 12 100674906 6861655412 446795963 4054123 93.58 97
09-JAN-98 13 102904875 6915160072 457913182 4141570 93.48 88
09-JAN-98 15 104438603 7174724422 480670786 4151163 93.40 72
09-JAN-98 16 104788896 7319570070 489984931 4152501 93.40 81
09-JAN-98 17 105112494 7435093265 499004688 4164244 93.38 65
12-JAN-98 9 21383330 223493743 20025092 715654 91.82 86
12-JAN-98 10 23337617 442097895 31239861 716584 93.29 119
12-JAN-98 11 26579418 661404543 43348023 766867 93.70 115
12-JAN-98 12 27133692 791029898 56354280 768134 93.11 111
12-JAN-98 13 27425634 941635522 67690129 769983 93.01 92
12-JAN-98 14 27730431 1102796144 80658299 773013 92.87 110
12-JAN-98 15 30132193 1215484215 92169035 831416 92.60 112
12-JAN-98 16 31519556 1286928131 104884564 839120 92.04 112
12-JAN-98 17 32192568 1349374881 118364177 843412 91.43 87
13-JAN-98 9 39654788 1953064586 171333381 1045362 91.40 69
13-JAN-98 10 41182792 2132339582 180789629 1059852 91.68 105
13-JAN-98 11 43391807 2287353673 192757640 1124912 91.73 113
13-JAN-98 12 44387992 2414892249 204647029 1187568 91.68 104
13-JAN-98 13 45580323 2611785449 215742476 1248375 91.88 72
13-JAN-98 14 46855540 2679866704 226297998 1322320 91.70 115
13-JAN-98 15 47835931 2828377188 237516902 1406846 91.74 124
13-JAN-98 16 48771648 2971134002 248749540 1464877 91.76 99
13-JAN-98 17 49873592 3117114968 260244269 1511966 91.78 94
14-JAN-98 9 68814298 3475724842 327507353 2087134 90.76 93
14-JAN-98 10 70363786 3583552575 337195620 2139976 90.77 93
14-JAN-98 11 72754325 3692592765 348613345 2223863 90.74 105
14-JAN-98 12 74722329 3818847991 361406577 2286163 90.72 98
14-JAN-98 13 76293598 3981895698 371916819 2376222 90.84 94
14-JAN-98 14 77645443 4110976040 381425889 2472450 90.89 96
14-JAN-98 15 79080620 4253997135 392573117 2577627 90.94 92
14-JAN-98 16 81151182 4391073056 403495111 2674584 90.98 71
14-JAN-98 17 81274449 4462552481 414417271 2690378 90.88 71
15-JAN-98 9 87309595 4676232216 441873096 2869487 90.72 64
15-JAN-98 10 87753573 4751451320 451979608 2874336 90.66 77
15-JAN-98 11 89780710 4906233843 461458156 2877777 90.76 91
15-JAN-98 12 91824610 5223159140 469468174 2948786 91.17 61
15-JAN-98 13 95406491 5393132322 477790421 3059775 91.29 85
15-JAN-98 14 96915119 5579894714 488350832 3169418 91.40 95
15-JAN-98 15 98653351 5748607267 499549130 3272763 91.46 80
15-JAN-98 16 99483927 5966142821 507671884 3321015 91.63 80
15-JAN-98 17 102069939 6074046876 516658119 3396877 91.63 55
16-JAN-98 9 17000809 72178149 12468965 635337 86.02 60
---------- ---------- ---------- ---------- ------ ----------
avg 55400860.1 3138276588 248788294 1923567.51 92.04 86.50
Report components:
db block gets The sum (i.e. logical reads) of the values of these statistics is the total number requests for data.Report Projection (Hits vs. I/Os):Consistent gets This value includes requests satisfied by access to buffers in memory.
physical reads The value of these statistics is the total number of requests for data resulting in access to data files on the disk.
db buffer cache hit ratio The projection of logical (in memory) vs. physical reads (on disk). ((logical reads - physical reads)/logical reads)*100
Name Value RemarksNote: It is evident from the above projections that the average logical read (i.e. total buffer gets) is much higher than the average physical read which indicates that the majority of I/O activity is happening in SGA (i.e. the real memory allocated for ORACLE) rather than on the disks. The Hit - Ratio projection shows positive results (i.e. 92%), which is more than an average value. Overall, the performance of SGA is excellent and has been adequately configured.Average Hit - Ratio 92% Excellent result
Average Physical Reads 70000/s Normal according to application
Average Physical Writes 600/s Normal according to application
Average Logical Reads 890000/s Excellent result
Average Sessions 86 Normal
Data Dictionary Hit Ratio Report:(Tab - 8)
PS: The statistics are recorded for two weeks at every one-hour interval, starting at 9 AM and ending at 5 PM.Check Check Cache Cache HitDate Time GETS Getmiss Ratio Ratio
--------------------------------------------------
06-JAN-98 17 12313256 37904 .307830845 99.69
08-JAN-98 10 25852641 50073 .193686208 99.81
08-JAN-98 10 25857246 50073 .193651714 99.81
08-JAN-98 10 25863066 50082 .193642935 99.81
08-JAN-98 12 27120799 53711 .198043575 99.80
08-JAN-98 13 27825243 53959 .193921038 99.81
08-JAN-98 14 28509692 54326 .190552743 99.81
08-JAN-98 15 29059747 54692 .188205355 99.81
08-JAN-98 16 29589798 54834 .185313871 99.82
08-JAN-98 17 30901290 55167 .178526528 99.82
09-JAN-98 9 35814970 56169 .156831068 99.84
09-JAN-98 10 36386783 56355 .154877665 99.85
09-JAN-98 11 36968603 56935 .154009065 99.85
09-JAN-98 12 37549096 57289 .152570917 99.85
09-JAN-98 13 38053157 58077 .152620714 99.85
09-JAN-98 15 40781540 66781 .163753012 99.84
09-JAN-98 16 41265772 67953 .164671583 99.84
09-JAN-98 17 41612906 69460 .166919369 99.83
12-JAN-98 9 4231680 17417 .411585942 99.59
12-JAN-98 10 4795764 19947 .415929558 99.59
12-JAN-98 11 5442589 21499 .395014211 99.61
12-JAN-98 12 5924844 22233 .375250386 99.63
12-JAN-98 13 6274203 23145 .368891475 99.63
12-JAN-98 14 6845756 24409 .356556675 99.64
12-JAN-98 15 7410563 25456 .343509663 99.66
12-JAN-98 16 7920304 26569 .335454296 99.67
12-JAN-98 17 8385038 27594 .329086165 99.67
13-JAN-98 9 11636921 31373 .269598805 99.73
13-JAN-98 10 12367056 31661 .256010808 99.74
13-JAN-98 11 13696666 32324 .235999038 99.76
13-JAN-98 12 14210934 32683 .229984883 99.77
13-JAN-98 13 14559632 32997 .226633475 99.77
13-JAN-98 14 15154990 33550 .221379229 99.78
13-JAN-98 15 15658082 34050 .217459584 99.78
13-JAN-98 16 16140156 35024 .216999142 99.78
13-JAN-98 17 16542597 35447 .214277117 99.79
14-JAN-98 9 21760454 36453 .167519483 99.83
14-JAN-98 10 22421407 37230 .166046671 99.83
14-JAN-98 11 22974621 37760 .164355268 99.84
14-JAN-98 12 23509947 38982 .165810667 99.83
14-JAN-98 13 23880092 39226 .164262349 99.84
14-JAN-98 14 24359150 39591 .162530302 99.84
14-JAN-98 15 24811228 39865 .160673224 99.84
14-JAN-98 16 25191628 39981 .158707488 99.84
14-JAN-98 17 25560440 40261 .157512938 99.84
---------- ---------- ---------- ---------
avg 18190019.5 36178.9583 .317143356 99.68
Report Components:
Data Dictionary Hit Ratio: The hit ratio projects the performance of cache allocated for data dictionary activities (i.e. the ORACLE data dictionary manipulation for user request, if not enough cache is allocated then misses on request will occur and the result is a degradation in performance). The value should not exceed 10% to 15%. The SHARED_POOL_SIZE parameter setting effects the value.
Gets: This column shows the total number of requests for information on the corresponding item. For example, the row that contains the statistics for the file descriptions has the total number of requests for file description data.
Getmisses: This column shows the number of data requests resulting in cache misses.
Report Projection (miss vs. gets & hits):
Name Value Remarks
Average Gets 18190019 Excellent (The cache allocation is adequate). That indicates that the shared pool size is set to its correct value.
Average Getmisses 36180 The value is considerably low compare to Gets. Average miss vs. gets .03% The projection is excellent. The maximum ratio. limit is 10% to 15%.
Average data dictionary hit ratio 99.63 Excellent projection.
Summary of Hit Ratios Projection:
Name Value Remarks
DB Buffer Cache Hit Ratios Average 92.00% Excellent Projection
Data Dictionary Cache Hit Ratios Average 99.63% Excellent Projection
Library Cache Hit Ratios Average 99.93% Excellent Projection
Session Hit Ratios Average 65.% Low Projection
Note: All hit ratios project excellent results (i.e. 80% to 100%) except for the Hit Ratio session (the ideal value is 80% to 90% the reason is the high temporary segments activities - discussed later), that indicates the memory allocated for I/Os are adequate. Accordingly, the database performance is at an optimum. Sometimes large rollback entries and large sorting in temporary segments influence the hit ratios. However, in the current scenario, the application is either read-only (i.e. the complex DSS queries during daily production phase) or write-only (i.e. information generation during data loading phase). Therefore, the rollback entries impact on hit ratios is less. Temporary segments to a certain extent influence the session-hit ratio since the adhoc DSS queries perform large frequent sorts. The sorts can be performed either in memory (i.e. by assigning large SORT_AREA_SIZE) or on disk (i.e. if ORACLE requires more sort area than is available in memory, then the sort takes place on disk i.e. on a temporary segment in the database). Once the temporary segment is allocated, Oracle tries to keep the cost of the sort to a minimum by writing data to and from the temporary segment in an unformatted fashion. Since the temporary segment activity is performed on unformatted data, Oracle does not use the consistent get mechanism to read the data - and no logical reads are recorded! Oracle performs physical reads and writes to move the data to and from the temporary segment. As a result, it is possible to have a low session hit ratio at peak hour. But the overall hit ratio is 92%, which indicates that a well-balanced configuration has been carried out. The parameters that mitigate the influence of temporary segments are discussed later in this document. The temporary segment usage is illustrated below.
Sort Usage Statistics: (Tab - 9)
Note: According to the above statistics (Tab - 9), for the average of 6 users load, 25% of the total temporary segments (i.e. Tablespace TEMP01) are used. The load is substantial for any database, which is a common phenomenon for data warehouse database. Therefore, it is obvious for the session-hit ratio to get influenced by the temporary segments (i.e. the spectrum of low and high value projection). In the exiting configuration, by assigning a large and dedicated (i.e. temporary only) tablespace of 18Gig size for the temporary segment, adequate room has been provided to the sorts to grow randomly and to keep the balance of buffer usage. The configuration has been carried out according to the requirement.Check Check Tablespace Current Total Used Total UsedDate Time Name Users Extent Extent Blocks blolcks
--------- ----- ---------- ------- ------ ------ ---------- ----------
09-JAN-98 13 TEMP01 5 160 28 1229600 215180
09-JAN-98 15 TEMP01 2 160 12 1229600 92220
09-JAN-98 16 TEMP01 2 160 11 1229600 84535
09-JAN-98 17 TEMP01 2 160 2 1229600 15370
12-JAN-98 9 TEMP01 3 72 70 553320 537950
12-JAN-98 10 TEMP01 8 77 12 591745 92220
12-JAN-98 11 TEMP01 12 77 15 591745 115275
12-JAN-98 12 TEMP01 14 77 30 591745 230550
12-JAN-98 13 TEMP01 6 77 13 591745 99905
12-JAN-98 14 TEMP01 9 77 35 591745 268975
12-JAN-98 15 TEMP01 10 77 33 591745 253605
12-JAN-98 16 TEMP01 10 77 69 591745 530265
12-JAN-98 17 TEMP01 9 77 32 591745 245920
13-JAN-98 9 TEMP01 4 77 18 591745 138330
13-JAN-98 10 TEMP01 10 77 52 591745 399620
13-JAN-98 11 TEMP01 12 115 114 883775 876090
13-JAN-98 12 TEMP01 7 144 42 1106640 322770
13-JAN-98 13 TEMP01 7 144 15 1106640 115275
13-JAN-98 14 TEMP01 2 144 4 1106640 30740
13-JAN-98 15 TEMP01 6 144 18 1106640 138330
13-JAN-98 16 TEMP01 5 144 28 1106640 215180
13-JAN-98 17 TEMP01 3 144 13 1106640 99905
14-JAN-98 9 TEMP01 4 144 17 1106640 130645
14-JAN-98 10 TEMP01 4 144 4 1106640 30740
14-JAN-98 11 TEMP01 10 144 13 1106640 99905
14-JAN-98 12 TEMP01 11 144 21 1106640 161385
14-JAN-98 13 TEMP01 8 144 12 1106640 92220
14-JAN-98 14 TEMP01 4 144 104 1106640 799240
14-JAN-98 15 TEMP01 8 144 26 1106640 199810
14-JAN-98 16 TEMP01 6 144 19 1106640 146015
14-JAN-98 17 TEMP01 6 144 8 1106640 61480
15-JAN-98 9 TEMP01 3 144 3 1106640 23055
15-JAN-98 10 TEMP01 6 144 7 1106640 53795
15-JAN-98 11 TEMP01 10 144 15 1106640 115275
15-JAN-98 12 TEMP01 0 144 0 1106640 0
15-JAN-98 13 TEMP01 9 144 17 1106640 130645
15-JAN-98 14 TEMP01 9 144 22 1106640 169070
15-JAN-98 15 TEMP01 5 144 17 1106640 130645
15-JAN-98 16 TEMP01 6 144 125 1106640 960625
15-JAN-98 17 TEMP01 5 144 8 1106640 61480
16-JAN-98 9 TEMP01 4 66 5 507210 38425
16-JAN-98 10 TEMP01 3 66 3 507210 23055
16-JAN-98 11 TEMP01 7 66 22 507210 169070
16-JAN-98 12 TEMP01 5 80 80 614800 614800
16-JAN-98 13 TEMP01 5 93 7 714705 53795
16-JAN-98 14 TEMP01 1 93 1 714705 7685
16-JAN-98 15 TEMP01 2 93 7 714705 53795
16-JAN-98 16 TEMP01 2 93 11 714705 84535
16-JAN-98 17 TEMP01 3 93 3 714705 23055
19-JAN-98 9 TEMP01 4 19 19 146015 146015
19-JAN-98 10 TEMP01 2 58 56 445730 430360
19-JAN-98 11 TEMP01 8 136 102 1045160 783870
19-JAN-98 12 TEMP01 7 136 34 1045160 261290
19-JAN-98 13 TEMP01 2 136 6 1045160 46110
19-JAN-98 14 TEMP01 3 136 63 1045160 484155
19-JAN-98 15 TEMP01 3 136 3 1045160 23055
19-JAN-98 16 TEMP01 5 136 23 1045160 176755
19-JAN-98 17 TEMP01 1 136 10 1045160 76850
------- ------ ------ ---------- ----------
avg 6 118 27 904312.5 206567.5
2. I/O Parameters: This section explains the database parameters that influence the I/Os and their ramifications. Following are the parameters:
This parameter depicits the number DBWR background processes (i.e. the process is used to write the data from memory to disk.) that can simultaneously write to the database from the SGA. If any kind of database write hiccup syndrome is noticed, it is imperative to assign more than one DBWR process to reduce the contention. The number of DBWR processes should be proportional to the number of transactions and users that updates the database simultaneously. In general, one DBWR process for every 50 on-line (query and small updates) users, and one DBWR process for every two batch jobs should update the database. For a scenario of 100 on-line users and four batch jobs running concurrently, a 4 DBWR process should be assigned.
In the current configuration, the parameter DB_WRITERS is set to 10 (i.e. ten DBWR processes have been assigned to perform the database write). The configuration is in commensurate with the existing load and nature of transactions. During the production phase, 60 to 120 on-line users are logged on and more than 50 large queries with a substantially frequent random write (i.e. sorts on temporary segments) occur on the database. During data load phase, a large amount of batch writes occur on the database. According to load statistics, the configuration is adequate.
II DB_BLOCK_SIZE
This parameter determines the size of data blocks that read and write to the database. The performance gain obtained by using a larger block size is significant for both OLTP and batch applications. In general, each doubling of the database block size will reduce the time required for I/O-intensive batch operations by approximately 40 percent.
In the current configuration, the parameter DB_BLOCK_SIZE is set to 8192 (i.e. 8K). This is a good size for the existing load and the operating system block size. If the load on database increases in the future, the value can be doubled. ORACLE on Digital 64-bit Unix supports up to a 32K block size. Therefore, it can increase the DB block size to 16K. This exercise will accentuate the throughput significantly. Note that this process involves the recreation of the database.
III DB_FILE_MULTIBLOCK_READ_COUNT
This parameter helps determine the number blocks that are read at a time by the database during full table scans. The ideal value for an 8K database block size is 32. Since this parameter only affects the performance of full table scans, the large reads are benefited (i.e. the query runs faster) more than small concurrent transactions.
In the current configuration, the DB_FILE_MULTIBLOCK_READ_COUNT parameter is set to 32. The value is set according to the block size and the transactions requirement. The value can be increased later if the DB block size is increased to 16K or 32K. By assigning a high value, a substantial gain can be achieved in the case of large queries performing a full table scan.
IV SORT_AREA_SIZE
The query performing sorts incur a major overhead on the resources in the case of large tables. In general, the sorting is taking place in temporary segments (i.e. on disk) of the database. This adds I/O overhead to the database and sometimes drastically slows down the performance (i.e. the scenario like SELECT ORDER BY, SELECT GROUP BY, SELECT DISTINCT, CREATE INDEX etc.). The SORT_AREA_SIZE parameter can be set to an optimum value so that the sorting can be adequately performed in memory rather than on disk.
In the current scenario, the parameter is set to 3 megabytes. This has been sized so that most of the queries perform sorts on the large tables. The size is not enough for the amount of sorts currently executed, but further incrementing the parameter may give unpredictable results due to an ORACLE limitation. Therefore, the parameter value is set optimally, and additionally a large space (i.e. 18gig of temporary tablespace) has been assigned on disk to perform additional sorts.
V SORT_DIRECT_WRITES
This parameter is set to True, enabling writes to temporary segments to bypass the data block buffers cache. As a result, sorting performance of queries requiring temporary segments significantly improves - the performance improvement is usually approximately 40 percent.
VI HASH_JOIN_ENABLED
This parameter is set to True, enabling the quires to perform Hash Joins (i.e. the joins and row filtration is carried out in memory by creating bitmapped tables. This process is considerably faster than the traditional joins) instead of NESTED LOOPS or MERGE JOINs. There are other supporting parameters for hash join run faster viz.
VII HASH_AREA_SIZE
Sets the maximum amount of memory that will be used for hash joins. The default is twice the SORT_AREA_SIZE setting. In the existing configuration, the value is set to 16MB, which is the optimum.
VIII HASH_MULTIBLOCK_IO_COUNT
Sets the number of blocks to be read/written at a time while doing disk I/O for hash joins. The parameter is set 8, which is according to the DB block size.
Lets discuss each schema design and their ramifications.I Common Sales Data (Schema CSD)II Material Management & Sales (Schema DW)
III Financial Management (Schema FI)
The schema design (i.e. the data modeling) has been performed in a snow-flake manner; this is the traditional data modeling normally performed for transactional database. This does not contribute much flexibility to build DSS quires. In other words, the quires have to complete multiple table joins in order to extract the information. Since the tables are normally large or tend to have a large size in data warehouse, any such complex queries with multiple joins slow down the performance. The normal practice of a data warehouse repository is to denormalize the tables and to keep the maximum information in a minimum number of tables.
The schema design has been performed in a denormalized star fashion. The existing design has been performed according to the requirement. The DSS quires take maximum advantage of the design. The quires can be written by having fewer table joins; the lesser the joins, the better the performance. The advantage of a star schemas and star quires are discussed later in this document.
III Financial Management (Schema FI)
The schema design has been performed in a denormalized star fashion. The design has been performed according to the requirement. The DSS quires take maximum advantage of the design. The quires can be written by having fewer table joins; the lesser the joins, the better the performance. The advantage of star schemas and star quires are discussed later in this document.
When a star schema is queried, dimension tables are usually involved in the query. Since dimension tables contain the Name or Description columns commonly used by queries, the dimension table will always be used by star queries unless the queries specifically refer to the ID values. A star query therefore typically has two parts to its where clauses: a set of joins between the fact table and the dimension tables, and a set of criteria for the Name columns of the dimension tables.
The star query performance is much faster than any other conventional query (i.e. complex join in any directions). Since query joins involve many small dimension tables (i.e. can be searched by index range scan) with one large fact table that can be searched by composite primary key index scan, the overall performance is much better. Star query takes maximum advantage of the ORACLE PARALLEL QUERY option if implemented. The star query execution path may require over 1000 times fewer block reads that the traditional execution path.
Impact on Performance Due to DSS Query Design: There are 30 to 50 queries running at peak hours against all the schemas as mentioned above. This has been monitored so that almost all the quires involve string manipulation (viz. string concatenation ||, wild card search %, LTRIM, RTRIM, SUBSTR etc.). Any such string manipulation will always suppress the index from queries and this will slow down the speed tremendously. Additionally, the quires are not always designed according to the star schema requirement. If such queries can be redesigned, a substantial performance throughput can be achieved. A correctly designed query can accentuate performance by 60% to 80%.
Transaction Load Analysis
Below is the projection of the overall transaction
load on the database (P011):
| Number of Sessions | 40 to 100 average and peak |
| Number of Transactions | 1 to 5 per second |
| Number of Physical Writes | 70000 per second
average |
| Number of Physical Reads | 600 per second
average |
| Number of Queries | 25 to 50 average and peak |
Note: In light of database design and implementation, the above transactions load analysis projects a substantial load impact. To a certain extent, both the server and database have been geared to accommodate a tangible load and growth demand from the application. But there is still enough room to trade-off various sectors of the database (viz. tablespace re-organization, DSS queries redesign etc.) that had been discussed earlier. There are other pivotal features of ORACLE 7.3 that can be implemented in order to attain more performance gain viz.
Partition views allow you to spread the data from single
table across multiple tables. A view can be created by a single query using
the union operator. For example, a large sales has a period bucket (i.e.
yearly sales bucket), the table can be split into many small tables for
each bucket (viz. 1991, 92, 93 etc.). Combining all such bucket tables
using the ORACLE SELECT UNION ALL option can create a sales view. Therefore,
any query that looks for the information from a particular bucket performs
a search on that bucket table rather than on a single large sales table.
The configuration provides an incredible performance. However, the only
disadvantage of partition views is the data load to base tables and maintenance
of the views. These difficulties can be eliminated completely by upgrading
ORACLE 7.3 to ORACLE 8. ORACLE 8 supports the explicit table and index
partitioning. This feature is discussed later in this document.
II Oracle Parallel Query Option
The key feature of 7.3 is parallel query option (i.e. built in to database). This feature can accentuate the large complex queries to a great extent especially when they are running on a multi-processor server. The result is remarkable since the parallel options invoke multiple processes to utilize spare system resources to reduce the time required to complete tasks. The parallel option does not reduce the amount resources required by the processing; rather, they spread the processing burden across multiple CPUs. As the data warehouse server is comprised of 6 CPUs and a large number of disks arrays, the parallel option can have a significant impact on the performance of the database and queries. Lets see how SMP (symmetric multiprocessors) react to OPQ:
The Oracle parallel query option takes advantage of the
mechanism best by spreading more than one Query Server onto different
CPUs so that multiple query servers and CPUs accomplish a single database
request. The number of query servers is decided by the degree of parallelism
defined at the object level and in the query. The degree of parallelism
in this scenario is of a single dimension i.e. the single Oracle
instance coordinating with multiple Query Servers. The degree
of parallelism can be made two-dimension by implementing the Oracle
Parallel Server. The Oracle parallel server (though the option is expensive)
extends tremendous leverage over multi- processor servers. More than one
Oracle instance contributes computing power to the large data warehouse
database. It is suggested that for future growth of the database ( i.e.
anticipated 500Gig by the end of year-98), OPS should be considered
as a key technology enhancement.
When Data Partition is Upcoming Demand of Very Large Database (VLDB) ORACLE8 Lights the Way
It is strongly suggested that to upgrade ORACLE 7.3 to ORACLE8, the pivotal feature is explicit data partition. Orcale8 allows you to divide the storage of tables into smaller units of disk storage called partitions. Each partition of a table has the same logical attributes. For example, each table partition contains the same columns with the same data types and integrity constraints. But each table partition can have different physical characteristics. For example, Oracle8 can store each partition of a table in a separate tablespace, and each partition can have different storage settings for PCTFREE, PCTUSED, and so on.
Oracle8 supports only range-partitioned tables. A rows partition key value determines in which partition Oracle8 stores a row. A tables partition key is a column or order set of columns (as many as 16) that characterizes the physical partitioning of table rows. See examples on the following page (Customers Table).
Rows in Data Partitions:CREATE TABLE usa_custmers( id NUMBER(5) PRIMARY KEY,
lastname VARCHAR2(50) NOT NULL,
firstname VARCHAR2(50) NOT NULL,
address VARCHAR2(100),
city VARCHAR2(50),
state VARCHAR2(2),
zipcode VARCHAR2(15),
phone VARCHAR2(15),
fax VARCHAR2(15),
email VARCHAR2(100) )
PARTITION BY RANGE ( state )
(PARTITION p1 LESS THAN (H)
TABLESPACE data01
(PARTITION p2 LESS THAN (MI)
TABLESPACE data02
(PARTITION p3 LESS THAN (NM)
TABLESPACE data03
(PARTITION p4 LESS THAN (S)
TABLESPACE data04
(PARTITION p5 LESS THAN (MAXVALUE)
TABLESPACE data05
To demonstrate Oracle8 placing rows into a range partitioned table, visualize what transpires when an application inserts a customer from the state Arkansas. Oracle8 performs an ANSI VARCHAR2 comparison with the first character in the state code AR with the value that defines the first table partition p1. Since A precedes F, Oracle8 places the new row into partition p1, which is physically stored as data of tablespace DATA01. In other words, Oracle8 creates the buckets for the different range of stares. Therefore, while accessing the customers of a particular state or a range of states, Oracle8 performs searches in the bucket related to the state rather than in full table. The access is incredibly faster compared to a conventional table implementation. All of the above new features can be taken into consideration for a demanding growth of data warehouse database. It is said prevention is always better than cure.