Higher Availability
Using intelligent partitioning strategies, Oracle8 can help meet the increasing availability demands of VLDBs. Oracle8 reduces the amount and duration of scheduled downtime by providing the ability to perform downtime operations when the database is still open and in use. The key to higher availability is partition autonomy, the ability to design partitions to be independent entities within the table. For example, any operation performed on partition X should not impact operations on a partition Y in the same table.
Greater Manageability
Managing a database consists of moving data in and out, backing up, restoring and rearranging data due to fragmentation or performance bottlenecks. As data volumes increase, the job of data management becomes more difficult. Oracle8 supports table growth while placing data management at a finer-grain, partition level. In Oracle7, the unit of data management was the table, while in Oracle8 it is the partition. As the table grows in Oracle8, the partition need not also grow; instead the number of partitions increases. All of the data management functions in Oracle7 still exist in Oracle8. But with the ability to act against a partition, a new medium for parallel processing within a table now is available. Similar rules apply to designing a database for high availability. The key is data-segment size and to a lesser degree, autonomy.
The strategy for enhanced performance is divide-and-conquer through parallelism. This paradigm inherently results in performance improvements because most operations performed at the table level in Oracle7 now can be achieved at the partition level in Oracle8. However, if a database is not designed correctly under Oracle8, the level of achievable parallelism and resulting performance gains will be limited. The table partitioning strategy used in Oracle7 may not necessarily be adequate to make optimal use of the Oracle8 features and functionality.
How Partition is done?
The pivotal feature of Oracle8 is explicit data partition. Orcale8 allows you to divide the storage of tables into smaller units of disk storage called partitions. Each partition of a table has the same logical attributes. For example, each table partition contains the same columns with the same data types and integrity constraints. But each table partition can have different physical characteristics. For example, Oracle8 can store each partition of a table in a separate tablespace i.e. located on different physical disk space, and each partition can have different storage settings for PCTFREE, PCTUSED, and so on.
Partitioned Tables
Oracle8 supports only range-partitioned tables. A row’s partition key value determines in which partition Oracle8 stores a row. A table’s partition key is a column or order set of columns (as many as 16) that characterizes the physical partitioning of table rows. See examples on the following page (Customers Table).
CREATE TABLE usa_custmers
( id NUMBER(5) PRIMARY KEY,
lastname VARCHAR2(50) NOT NULL,
firstname VARCHAR2(50) NOT NULL,
address VARCHAR2(100),
city VARCHAR2(50),
state VARCHAR2(2),
zipcode VARCHAR2(15),
phone VARCHAR2(15),
fax VARCHAR2(15),
email VARCHAR2(100) )
PARTITION BY RANGE ( state )
(PARTITION p1 LESS THAN (‘H’)
TABLESPACE data01
(PARTITION p2 LESS THAN (‘MI’)
TABLESPACE data02
(PARTITION p3 LESS THAN (‘NM’)
TABLESPACE data03
(PARTITION p4 LESS THAN (‘S’)
TABLESPACE data04
(PARTITION p5 LESS THAN (MAXVALUE)
TABLESPACE data05
Rows in Data Partitions:
To demonstrate Oracle8 placing rows into a range partitioned table, visualize what transpires when an application inserts a customer from the state Arkansas. Oracle8 performs an ANSI VARCHAR2 comparison with the first character in the state code AR with the value that defines the first table partition p1. Since A precedes F, Oracle8 places the new row into partition p1, which is physically stored as data of tablespace DATA01. In other words, Oracle8 creates the buckets for the different range of states. Therefore, while accessing the customers of a particular state or a range of states, Oracle8 performs searches in the bucket related to the state rather than in full table. The access is incredibly faster compared to a conventional table implementation.
MAXVALUE
Of particular interest in this example is the declaration of partition P5. This partition stores all rows with a value greater than the upper bound of the previous partition, P4. For example, when you insert a new customer from Wyoming, Oracle8 places the new row into partition P5, which is physically stored in a data file of tablespace DATA05. If the USA_CUSTOMER table did not include a partition with an upper bound MAXVALUE, Oracle8 would not allow applications to insert customers from SC, SD, TN, TX, UT, VA, VT, WA, WV, WI, and WY.
Partitioned Indexes
Oracle8 also supports range-partitioned indexes for non-clustered tables. Just as with tables, each partition of an index has the same logical attributes (index columns) but can have different physical characteristics (tablespace placement and storage settings). An index’s partition key determines in which partition Oracle8 stores index entries. An index’s partition key must include one or more of the columns that define the index. The declaration of index partition ranges is identical to declaring table partitions.
The data partitioning can incredibly accentuate the throughput of any large and complex queries since the queries against a partitioned table perform a full scan on a small partition instead of the whole table. Data partitioning is a broad new feature of Oracle8 – this article just scratches the surface. There are many other related issues to understand about table and index partitioning. Partition maintenance operations, such as moving splitting, rebuilding, and dropping partitions, are challenging topics for a DBA to master. My endeavor here is to pave the way but it is always said "last but not least".
STAR SCHEMAS
Almost all of the data in a data warehouse originated from an operational system. However, even if the data exists in a relational schema in an operational system, a transaction-oriented schema is not necessarily appropriate for a data-warehousing application. A typical operation in on-line transaction process (OLTP) is a "transaction." In most applications, a transaction consists of the retrieval, insertion, or update of only a handful of records. For example, a new purchase order requires information about the customer, and the products being ordered. Operational systems are typically optimized to allow the application to quickly locate these individual records.
The typical data warehousing operation involves a much larger number of records. The end-user of a data warehouse is not interested in a single purchase order. Instead, the end-user will want to examine all of the purchase orders for a given week, or for a given region. Data warehouses are used for a variety of purposes, from simple reporting to more complex analysis and sophisticated forecasting. But each of these data warehousing functions share the same characteristic of analyzing large amounts of data.
A highly normalized schema offers superior performance and efficient storage for OLTP schemas; and star schema provides similar benefits for data warehouses.
What is a Star Schema?
A "star schema" is a natural data representation for many data warehousing applications. A star schema contains one very large table (known as the FACT table), and multiple smaller tables (called DIMENSION tables).
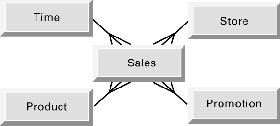
Example star schema
The SALES table contains information about the sales for each product at each store on a given day (e.g., the date of the transaction and the amount of total sales). The SALES table is very large, since a grocery-store chain could easily have millions of such entries per day.
In contrast, the TIME, PRODUCT, STORE, and PROMOTION tables are very small relative to the SALES table. In this schema, SALES is the FACT table; product sales are the basic units of analysis for this data warehouse. The other tables (TIME, PRODUCT, STORE, and PROMOTION) are the DIMENSION tables. These DIMENSION tables provide more details of the sales transactions, describing information about which products were sold, when and where the sales occurred, and what promotions might have influenced the sale.
This star schema is an intuitive representation of multidimensional ‘datacube’ in a relational environment. Each DIMENSION table represents a business dimension while the FACT table contains the contents of the ‘datacube,’ which in this case is the sales information for each product. For example, an end user may want to examine ‘sales by store by week,’ where STORE and TIME are dimensions of the query.
STAR QUERY PROCESSING IN ORACLE8
Oracle8’s star query algorithm represents a significant improvement over previous star query algorithms. Rather than relying on a join index, Oracle8’s algorithm utilizes single-table bitmap indexes, and integrates this bitmap technology seamlessly into a new star query join method. This new algorithm provides excellent performance, while utilizing less storage (bitmap indexes are highly compressed) and offering more flexibility in both the types of schemas and the types of queries that can be optimized. Let’s see how it works, Oracle8 processes a star query using two basic phases. The first phase retrieves exactly the necessary rows from the fact table. Because this retrieval utilizes bitmap indexes, it is very efficient. The second phase joins this "result set" from the fact table to the dimension tables. Star queries augment the throughput to great extent.
Oracle Parallel Query & Server Option
The key feature of Oracle8 is parallel query option (i.e. built in to database). This feature can accentuate the large complex queries to a great extent especially when they are running on a multi-processor server. The result is remarkable since the parallel options invoke multiple processes to utilize spare system resources to reduce the time required to complete tasks. The parallel option does not reduce the amount resources required by the processing; rather, they spread the processing burden across multiple CPUs. As the data warehouse server is comprised of 6 CPUs and a large number of disk arrays, the parallel option can have a significant impact on the performance of the database and queries. Let’s see how SMP (symmetric multiprocessors) react to OPQ:
SMP architecture entails multiple processors sharing common memory and disk storage and running under a single operating system image. The operating system leverages the available pool of CPUs and allocates tasks so that processes work in parallel to accomplish a set of tasks. The SMP architecture allows a degree of parallelism in execution. Because multiple tasks can run simultaneously, a separate processor manages each one.
The Oracle parallel query option takes advantage of the mechanism best by spreading more than one Query Server onto different CPUs so that multiple query servers and CPUs accomplish a single database request. The number of query servers is decided by the degree of parallelism defined at the object level and in the query. The degree of parallelism in this scenario is of a single dimension i.e. the single Oracle instance coordinating with multiple Query Servers. The degree of parallelism can be made two-dimension by implementing the Oracle Parallel Server. The Oracle parallel server extends tremendous leverage over multi- processor servers. More than one Oracle instance contributes computing power to the large data warehouse database. Let’s see how OPS works.
Oracle Parallel Server, an option to Oracle8 Enterprise Edition, stands alone in providing Database Management Systems functionality and performance for loosely coupled systems. Oracle Parallel Server allows users on multiple nodes to access the same database simultaneously. Users benefit from the increased transaction processing power and higher availability of multiple computer systems. Through the use of parallel cache management, Oracle Parallel Server takes advantage of high availability, high performance, and incremental growth made possible by loosely coupled systems. Parallel Database technology can make it possible to overcome the memory and CPU limitations of a particular node, enabling a single clustered configuration to support a much larger user base. The Oracle Parallel Server is designed to take full advantage of all the benefits offered by loosely coupled systems. The diagram below displays an example of an Oracle Parallel Server implementation.
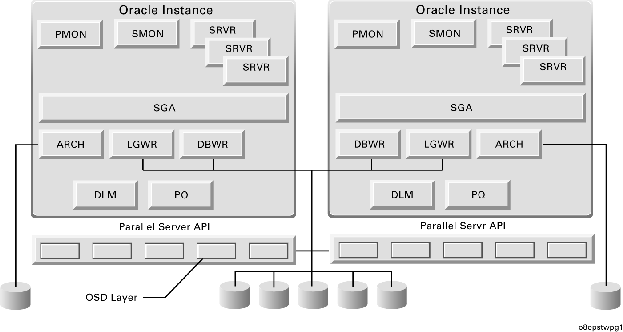
Oracle Parallel Server Cluster
Both the OPQ and OPS add tremendous muscle power to VLDBs.
Other New Parallel Server Performance Features for Oracle8: Introducing an extra level of DML locking via partitioned tables may affect performance of short transactions. To improve performance in the Oracle Parallel Server environment, you can turn off DML locking on selected tables with the ALTER TABLE DISABLE TABLE LOCK command. This disables both table and partition level DML locks. This allows extra traffic to the Integrated Distributed Lock Manager to be bypassed, thereby providing a performance benefit. DDL statements are not allowed on the selected tables when DML locking is disabled.
Disk affinity is further enhanced in Oracle8, providing performance improvements. Partition to node affinity information determines slave allocation and work assignment. This results in a fairly deterministic assignment of partitions to Oracle instances. For parallel DML, this results in an increased likelihood of buffer cache hits. For shared-nothing MPP systems, the Oracle Parallel Server assigns partitions to instances by taking the disk affinity into account. Affinity information that persists across transaction statements improves buffer cache hit ratios and reduces block pings between instances.
Oracle Parallel Server is a highly reliable system designed to provide high availability and scalable performance for applications, while minimizing communication overhead between cluster nodes and maximizing the performance of each cluster through parallel cache management and internal concurrency control. Oracle Parallel Server brings a number of very important benefits to the high-end and mid-range of enterprise computing. A number of major clustering architectures have emerged in the last decades and Oracle has been working closely with the key platform vendors in this field, to help the vendors provide the necessary high-speed network and shared disks required by the Oracle Parallel Server. The combination of the Oracle Parallel Server and the variety of clustering architectures in DEC Open VMS, all the major UNIX platforms, and Windows NT cluster vendors offer ideal solutions for many classes of applications which require scalability, high availability and high performance.
Oracle8 High – Availability Architecture:
The Oracle8 high availability architecture provides sophisticated features for minimizing the length and disruptiveness of unplanned database outages. By using these features, customers can greatly improve the total availability of their business systems. Oracle8 supports the following high availability features:
Standard recovery on a single node